1. Chaining MapReduce Jobs任务链
2. Join data from different data source
<1>. Changing MapReduce jobs
1.1Chaining MapReduce jobs in a sequence
MapReduce程序能够执行一些复杂数据处理的工作,通常的情况下,需要将这个任务task分割成多个较小的subtask,然后每个subtask通过hadoop中的job运行完成,然后教案subtask的结果收集起来,完成这个复杂的task。
最简单的就是“顺序”执行了。编程模型也比较简单。我们知道在MapReduce编程中启动一个任务JobClient.runJob(),这时仅仅到这个任务job完成了之后,该语句才能结束,所以如果想要顺序执行任务的话,只需要在每个任务完成之后重新开始一个新的任务。
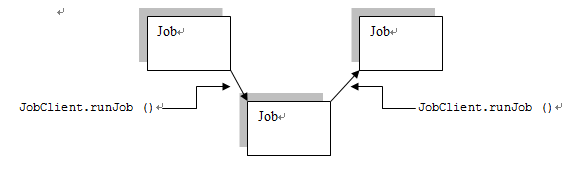
1.2Chaining MapReduce jobs with complex dependency
但是在更多的情况下仅仅按照顺序执行是完全不够的,在hadoop中提供了JobContrl类来封装一系列的job和这些job之间的依赖关系。
JobControl中提供了addJob方法将一个job添加到这个job的集合中;
同时每个每个job类提供了addDependingJob方法。
例如,我们现在需要运行5个job:job1, job2, job3, job4, job5,如果job2需要在job1运行完成之后,运行;job4需要在job3运行完成之后运行,最终job5需要在job2和job4运行完成之后才能运行。那么这时可以这样建立模型:

1.3Chaining preprocessing and postprocessing steps
hadoop中一个每个任务可以有多个Mapper和Reducer,这时程序的执行顺序如下:
The Mapper classes are invoked in a chained (or piped) fashion, the output of the first becomes the input of the second, and so on until the last Mapper, the output of the last Mapper will be written to the task's output.
也就是类似于linux下的管道命令mapper1 | mapper2 | reducer1 | mapper3 | mapper4。
<2>. Joining data from different sources
如果存在这样的两个数据源Customers和Orders,
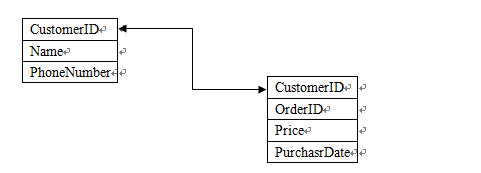
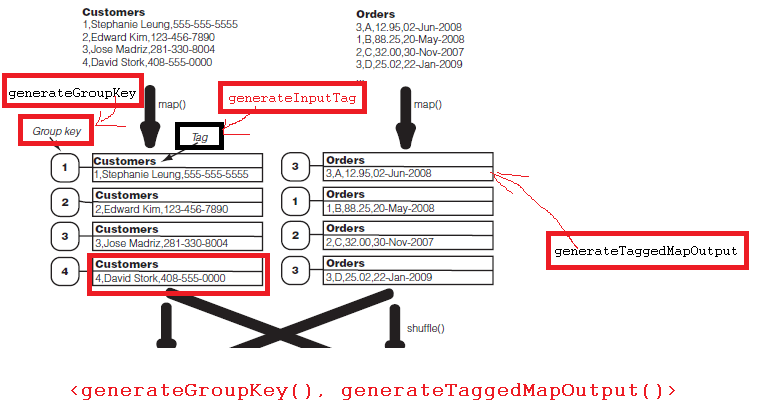
如果我们想要分析这个数据的话, 这时就需要使用hadoop的datajoin功能。首先我们来看看hadoop data join的流程。
首先map函数从Customers和Orders中读取数据,输出<K1-2, V1-2>,<K2-1, V2-1>;
然后hadoop开始partition,shuffle,这时和原先处理不同的是这里将把group key相同的打包,发送到一个reduce函数中;
这时reduce函数得到的将是group key相同的一组数据。

然后在reduce函数中,将执行data join形成combination,然后将combination发送到combine()函数输出每个结果record。

在hadoop中存在DataJoinMapperBase基类和DataJoinReducerBase基类用来实现data join。对于data join的mapper需要继承自DataJoinMapperBase,并且该mapper需要实现三个方法:
对于需要实现data join的reducer而言,需要继承自DataJoinReducerBase,这时需要重写方法combine,首先需要明确的是combine作用的对象:
For each tuple in the cross product, it calls the following method, which is expected to be implemented in a subclass. protected abstract TaggedMapOutput combine(Object[] tags, Object[] values);The above method is expected to produce one output value
from an array of records of different sources.
combine显然是针对的是an array of records of different sources,即:
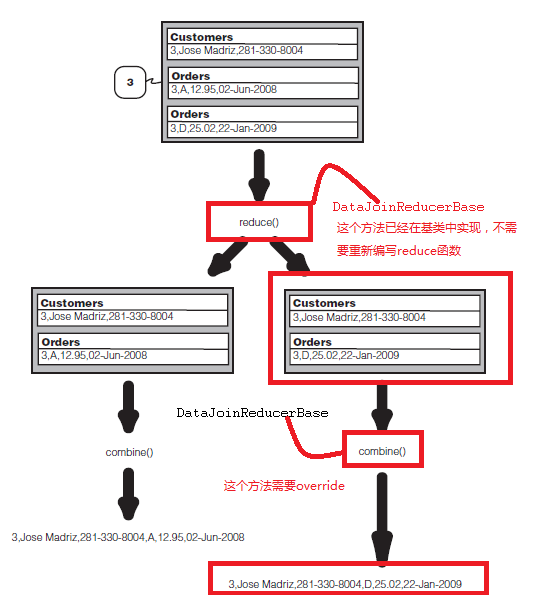
也就是说combine仅仅是负责得到最终的输出格式。
分享到:





相关推荐
NULL 博文链接:https://irwenqiang.iteye.com/blog/1453740
全书分为10章,系统地介绍了HDFS存储系统,Hadoop的文件I/O系统,MapReduce2.0的框架结构和源码分析,MapReduce2.0的配置与测试,MapReduce2.0运行流程,MapReduce2.0高级程序设计以及相关特性等内容。《MapReduce...
全书分为10章,系统地介绍了HDFS存储系统,Hadoop的文件I/O系统,MapReduce 2.0的框架结构和源码分析,MapReduce 2.0的配置与测试,MapReduce 2.0运行流程,MapReduce 2.0高级程序设计以及相关特性等内容。...
包括初识Hadoop、Hadoop基础知识、Hadoop开发环境配置与搭建、Hadoop分布式文件系统、Hadoop的I/O操作、MapReduce编程基础、MapReduce高级编程、初识HBase、初识Hive。通过本书的学习,读者可以较全面地了解Hadoop的...
【实例简介】 文档为PPT,与百度文库里的Hadoop大数据开发基础为一套,里面内容相对比较基础~可做基础学习资料PPT。...│ └── MapReduce高级编程.ppt └── 第6章 └── 基于knn的电影网站用户性别预测.ppt
1.shuffle机制详细讲解 2.MR案例多文件输出 3.MR案例partition使用 4.MR案例内容去重 5.MR案例敏感词汇过滤 6.MR案例自定义combiner的使用 7.MR案例倒排序索引 8.MR案例简单排序
《Hadoop高级编程——构建与实现大数据解决方案》本书关注用于构建先进的、基于Hadoop的企业级应用的架构和方案,并为实现现实的解决方案提供深入的、代码级的讲解。本书还会带你领略数据设计以及数据设计如何影响...
MapReduce作为一种分布式海量数据处理的编程框架,已经得到业界的...《MapReduce设计模式》面向中高级MapReduce开发者,涵盖了绝大部分MapReduce编程可能面对的场景,相信初学者和专家同样可以在本书中得到一些启示。
《深入理解大数据:大数据处理与编程...■ MapReduce高级程序设计技术 ■ MapReduce机器学习与数据挖掘基础算法 ■ 大数据处理算法与应用编程案例 这是本书很多实例的源代码 对很多进行大数据学习的朋友们会很有帮助
本书由 Hadoop 领域资深的实践者亲自执笔,首先介绍了 MapReduce 的设计理念和编程模型,然后从源代码的角度深入分析了 RPC 框架、客户端、JobTracker、 TaskTracker 和 Task 等 MapReduce 运行时环境的架构设计与...
《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》由Hadoop领域资深的实践者亲自执笔,首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和...
《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》由Hadoop领域资深的实践者亲自执笔,首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和...
《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》由Hadoop领域资深的实践者亲自执笔,首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和...
《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》由Hadoop领域资深的实践者亲自执笔,首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和...
《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理》由Hadoop领域资深的实践者亲自执笔,首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和...
首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和Task等MapReduce运行时环境的架构设计与实现原理,最后从实际应用的角度深入讲解了Hadoop的性能...
■ 大数据处理技术与Hadoop MapReduce简介 ■ Hadoop系统的安装和操作管理 ■ 大数据分布式文件系统...■ MapReduce高级程序设计技术 ■ MapReduce机器学习与数据挖掘基础算法 ■ 大数据处理算法与应用编程案例
首先介绍了MapReduce的设计理念和编程模型,然后从源代码的角度深入分析了RPC框架、客户端、JobTracker、TaskTracker和Task等MapReduce运行时环境的架构设计与实现原理,最后从实际应用的角度深入讲解了Hadoop的性能...
基本概述:本书由 hadoop 领域资深的实践者亲自执笔,首先介绍了 mapreduce 的设计理念和编程模型,然后从源代码的角度深入分析了 rpc 框架、客户端、jobtracker、tasktracker 和 task 等 mapreduce 运行时环境的架构...
详细讲述最新的单指令、多数据流指令和向量化等并行编程技术,介绍现代并行库,讨论如何珠联璧合地使用高级Intel工具与C#,并指导您巧妙使用新引入的轻型协调结构来开发自己的解决方案并解决最棘手的并发编程问题。...